私は昔から、良さそうな記事を見つけると、とりあえず保存する癖があります。
技術ブログ、Hacker News、AI ニュース、誰かが共有してくれた質の高い記事。まず Readwise に入れて、あとでゆっくり読もうと思う。
結果はたぶん想像できると思います。きっと同じような人も多いはずです。
保存する速度は、読む速度よりずっと速い。
時間が経つにつれて、Reader の Inbox はどんどん長くなり、未読も増えていきます。アプリを開いたときの感覚は、少しずつこう変わっていきました。
今日はまた、どれだけ読むものを溜めてしまったんだろう?
本来はこうであってほしいのに。
今日、本当に読む価値があるものは何だろう?
その後、問題はリーダーアプリそのものではないのかもしれないと気づきました。
問題は、「何を読むかを決める」という作業まで自分に残していたことです。
毎日何十本もの記事を前にしたとき、本当に消耗するのは読むことではありません。選別することです。
そこで小さなプロジェクトを作りました。
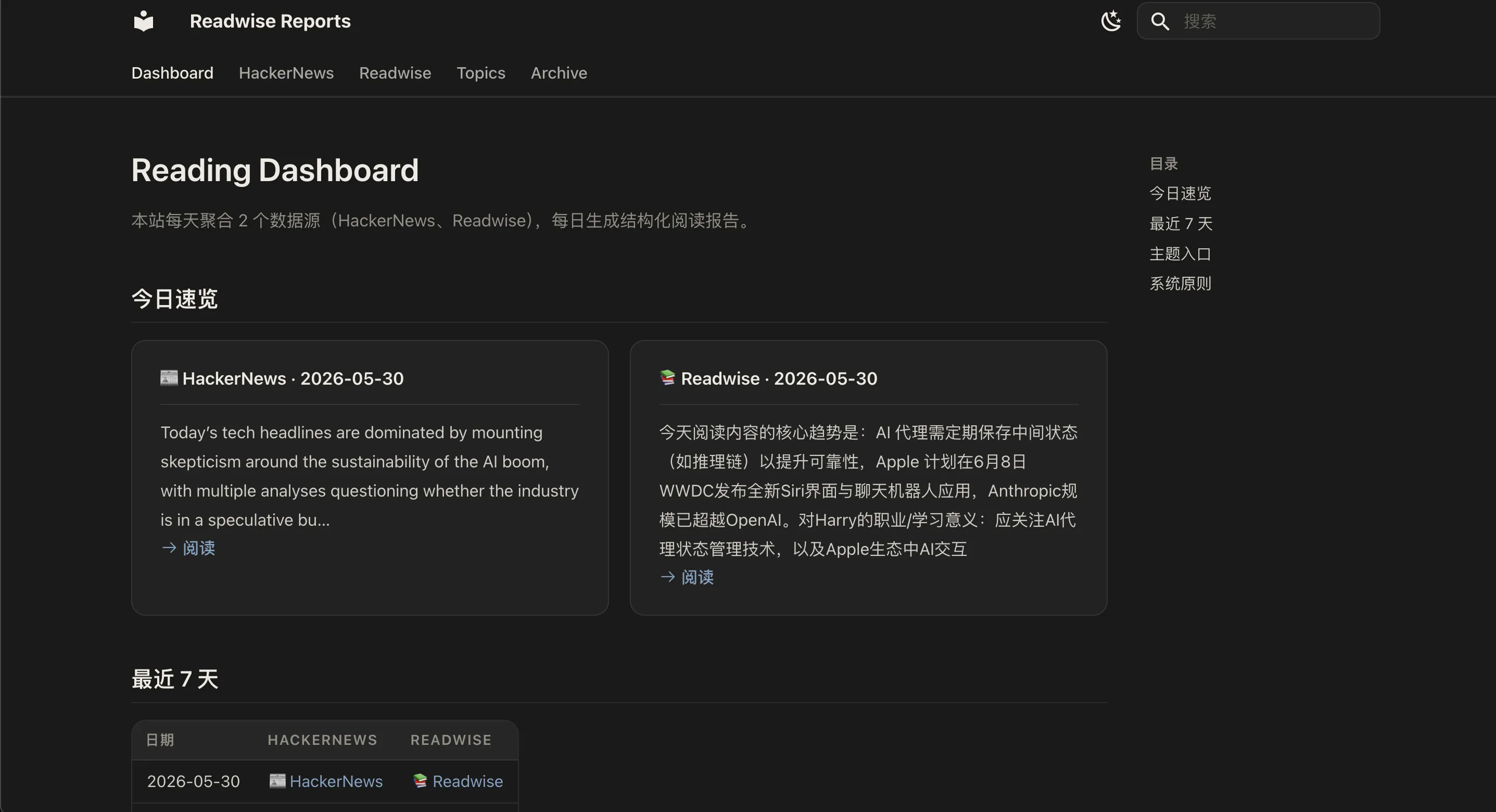
やっていることはシンプルです。毎日、自分が追っている情報源を自動で巡回し、日報を生成します。
今つないでいる情報源は二つです。
- Readwise
- Hacker News
AI がまず内容に目を通します。
- どれをしっかり読むべきか。
- どれは軽く眺めれば十分か。
- どれはそのままスキップしてよいか。
- ついでに要約も付ける。
最後に Markdown のレポートを生成し、リポジトリに保存して、簡単な Web サイトで表示します。
もともとあちこちに散らばっていた情報が、最終的には一枚の日報になります。
毎日サイトを開いたとき、目の前にあるのは数百本の候補記事ではなく、すでに並び替えられた読書リストです。
最初は、ただのスクリプトを書くつもりでした。
Readwise からデータを取る -> AI に要約させる -> Markdown を書き出す -> 終了。
でも途中で一つの問題に気づきました。
今日は Readwise。
明日は Hacker News かもしれない。
明後日は GitHub Trending かもしれない。
さらにその先には、どこかの Newsletter が来るかもしれない。
新しい情報源を追加するたびにメインフローを修正しなければならないなら、このシステムはすぐにスパゲッティになります。
そこで自分の中で一つルールを決めました。
一つのデータソースに、一つの Skill。
Readwise は一つの Skill。
Hacker News も一つの Skill。
今後新しい情報源を追加するなら、それもまた新しい Skill にする。
各 Skill は、自分の中で次の処理だけを担当します。
fetch -> dedup -> AI -> writeつまり:
取得
↓
重複排除
↓
AI 処理
↓
レポート生成それ以外のことは気にしなくていい。
そして真ん中に、とても小さな Kernel を置きました。この Kernel は、意図的に何も知りません。Readwise も知らない。Hacker News も知らない。将来どんな情報源が増えるかも知らない。
Kernel が担当するのは、これだけです。
- どんな Skill があるかを見つける
- Skill に共通機能を提供する
- 順番に実行する
ざっくり描くと、こういう構成です。
flowchart LR
subgraph SRC[データソース]
direction TB
RW0[Readwise]
HN0[Hacker News]
NX0[次のソース ...]
end
subgraph PLUG[Skills]
direction TB
RW1[readwise/]
HN1[hackernews/]
NX1[next-source/]
end
subgraph CORE[Kernel]
direction TB
REG[Registry]
--> RUN[Runtime]
--> SVC[AI · Store · Writer · Log]
end
subgraph OUT[Output]
direction TB
MD[Markdown Reports]
--> WEB[Portal Site]
DC[Discord]
end
RW0 --> RW1
HN0 --> HN1
NX0 -.-> NX1
SVC -. SkillContext .-> PLUG
PLUG --> MD
PLUG --> DC
私はこの構造がかなり気に入っています。
Kernel は、外で何が起きているかを永遠に知る必要がないからです。
Kernel は能力を提供するだけ。
何を取得するのか、どう取得するのか、どう処理するのかは、それぞれの Skill が自分で決めます。
もう一つ、自分で気に入っている小さなポイントがあります。
Skill の中で AI を呼ぶ方法は、常にこれだけです。
ctx.ai.complete(...)API Key が設定されていれば、OpenAI、Claude、Gemini を直接呼び出します。
一方で、パイプライン全体が Claude Code のような Agent の中で動いているなら、そのホスト Agent のモデル能力をそのまま使えます。
Skill から見ると、両者に違いはありません。
同じコードを変更する必要がないのです。
私はずっと、アーキテクチャの良し悪しを見るうえで、機能を追加しやすいかどうかは最重要ではないと思っています。
追加は誰でもできます。本当に難しいのは削除です。もしある日、ある情報源にはもう価値がないと判断したら、私はこれだけで済ませたい。
rm -rf skills/some-sourceそれで終わり。
登録表はない。
設定の同期もない。
システムのあちこちに散らばった、こういう条件分岐もない。
if (source === "xxx")次回起動したとき、Kernel はその Skill をスキャンできない。だから自然に消える。
日報にも出ない。
Web サイトにも出ない。
通知にも出ない。
世界は、その情報源が現れる前の状態に戻ります。
後からこのプロジェクトを振り返ると、自分が本当に作ったのは、読書ツールではなかったのかもしれないと思いました。
コンテンツが増え続けるという問題は、そもそも解決できません。
今日片づけても、明日にはまた増えます。
私が本当に解決したかったのは、別のことでした。
コンテンツ爆発の時代に、「何を読むかを決める」という一歩を外注すること。
AI に先に一通り読んでもらう。
システムに先にふるい分けてもらう。
最後に自分の前に残るのは、その日に読む価値が高い数本だけ。
それでも、全部は読めないのが普通です。
ただ今は、最初の一読を代わりにしてくれるものがあります。