我一直有个习惯:看到不错的文章就先存起来。
技术博客、Hacker News、AI 新闻、别人分享的高质量内容,先收进 Readwise,想着以后慢慢看。
结果大家应该都猜得到,估计大家都应该一样。
存的速度永远比读的速度快。
时间久了以后,Reader 里的 Inbox 越来越长,未读越来越多。打开 App 的感觉慢慢变成:
我今天又欠了多少内容没看?
而不是:
今天有什么值得看的东西?
后来我发现问题可能不在阅读器。
问题在于,我把「决定读什么」这件事,也留给了自己。
每天面对几十篇文章的时候,真正消耗精力的其实不是阅读,而是筛选。
所以我做了一个小项目:
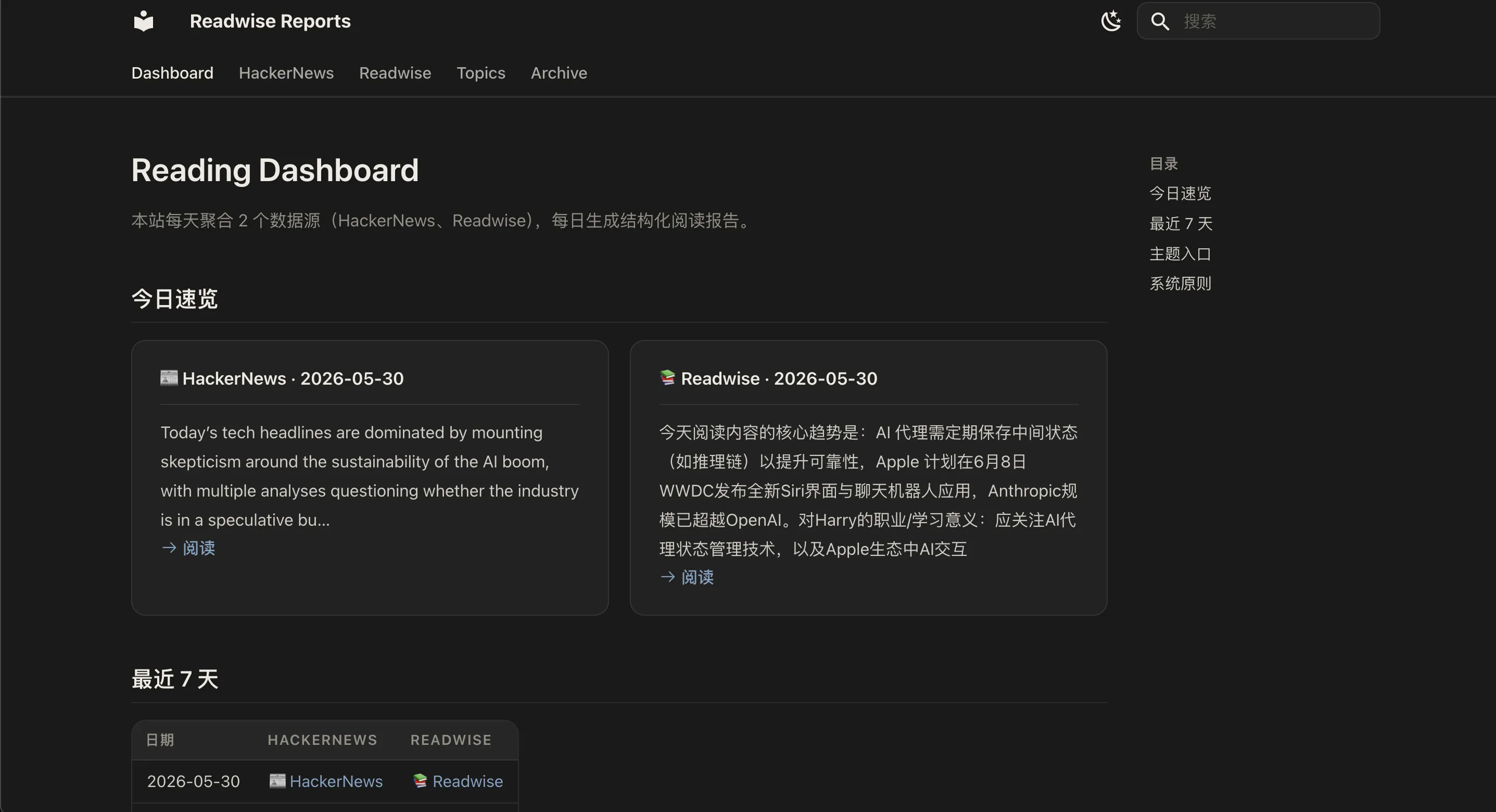
它做的事情很简单。每天自动把我关注的信息源扫一遍,然后生成一份日报。
现在接了两个来源:
- Readwise
- Hacker News
AI 会先帮我把内容过一遍。
- 哪些值得认真读。
- 哪些扫一眼就够。
- 哪些可以直接跳过。
- 再顺手给出摘要。
最后生成 Markdown 报告,归档到仓库里,再通过一个简单的网站展示出来。
于是原本散落在各个地方的信息,最后变成了一页日报。
每天打开网站的时候,我面对的不再是几百篇候选内容,而是一份已经排过序的阅读清单。
最开始的时候,我其实只是想写个脚本。
从 Readwise 拉数据 -> 丢给 AI 总结 -> 写个 Markdown -> 结束。
但写到一半的时候,我发现一个问题。
今天是 Readwise。
明天可能是 Hacker News。
后天可能是 GitHub Trending。
再往后可能是某个 Newsletter。
如果每加一个来源,都要回头修改主流程,那么这个东西很快就会长成一团意大利面。
所以后来我给自己定了一个规则:
一个数据源,对应一个 Skill。
Readwise 是一个 Skill。
Hacker News 是一个 Skill。
以后如果还要接新的来源,那也是一个新的 Skill。
每个 Skill 自己负责:
fetch -> dedup -> AI -> write也就是:
抓取
↓
去重
↓
AI 处理
↓
生成报告除此之外,什么都不用关心。
然后中间放了一个很小的 Kernel。它故意什么都不知道。不知道 Readwise。不知道 Hacker News。也不知道未来会接什么源。
它只负责:
- 找到有哪些 Skill
- 给 Skill 提供公共能力
- 按顺序执行
大概长这样:
flowchart LR
subgraph SRC[数据源]
direction TB
RW0[Readwise]
HN0[Hacker News]
NX0[下一个源 ...]
end
subgraph PLUG[Skills]
direction TB
RW1[readwise/]
HN1[hackernews/]
NX1[next-source/]
end
subgraph CORE[Kernel]
direction TB
REG[Registry]
--> RUN[Runtime]
--> SVC[AI · Store · Writer · Log]
end
subgraph OUT[Output]
direction TB
MD[Markdown Reports]
--> WEB[Portal Site]
DC[Discord]
end
RW0 --> RW1
HN0 --> HN1
NX0 -.-> NX1
SVC -. SkillContext .-> PLUG
PLUG --> MD
PLUG --> DC
我很喜欢这种结构。
因为 Kernel 永远不用知道外面发生了什么。
它只负责提供能力。
至于具体要抓什么、怎么抓、怎么处理,都交给 Skill 自己决定。
还有一个我自己挺喜欢的小细节。
Skill 里面调用 AI 的方式永远都是:
ctx.ai.complete(...)如果配置了 API Key,它会直接调用 OpenAI、Claude 或 Gemini。
如果整条流水线本身就在 Agent 里运行,比如 Claude Code,那么它又可以直接使用宿主 Agent 的模型能力。
对于 Skill 来说,两者没有区别。
同一段代码,不需要修改。
我一直觉得,一个架构好不好,新增功能其实不是最重要的指标。
因为大家都会加。真正难的是删。如果某天我觉得某个来源已经没有价值了。
我希望我只需要:
rm -rf skills/some-source然后事情就结束了。
没有注册表。
没有配置同步。
没有散落在系统各处的:
if (source === "xxx")下次启动的时候,Kernel 扫描不到这个 Skill,它就自然消失了。
日报里没有。
网站里没有。
通知里也没有。
世界恢复到它出现之前的样子。
后来回头看这个项目的时候,我发现自己真正做的,好像也不是一个阅读工具。
因为内容越来越多这件事,根本解决不了。
今天解决了,明天还会更多。
我真正想解决的是另外一件事:
在内容爆炸的时代,把「决定读什么」这一步外包出去。
让 AI 先替我过一遍。
让系统先替我筛一遍。
最后留给我的,是当天最值得读的那几篇。
读不过来仍然是常态。
只是现在,有个东西会替我先读第一遍了。